Neural Processes in PyTorch
Neural Processes¶
Recently, Deepmind published Neural Processes at ICML, billed as a deep learning version of Gaussian processes. In addition, Kaspar Martens published a blog post with some visuals I can't hope to match here. Before proceeding, I recommend checking out both.
This post is to show the link between these and VAEs, which I feel is quite illuminating, and to demonstrate some shortfalls of the method. I suggest a working knowledge of VAEs before proceeding. In addition, I will be briefly skimming past the theory of Neural Processes - reading the paper and Kaspar's blog are assumed prequisites.
Lastly, I'm going to point out what I consider to be some fairly major issues I have found with the method. I reached out directly to one of the authors of the paper to discuss these, but got no response. I am happy to discuss if people thing these shortfalls are a result of error and/or misinterpretation on my end, people think they are not a big deal or anything. I have not seen these covered or discussed anywhere else, so this is a discussion of what appear to be shortcomings in the approach, rather than an attack on the paper (which for the record I really like).
A recap of VAEs¶
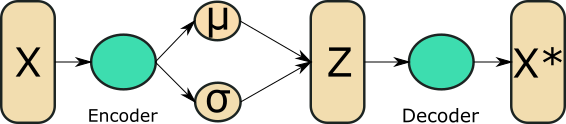
A VAE has a simple pipeline:
- Data, $X$ fed in 'encoder network' which ouputs a mean and variance for $q(Z \mid X)$.
- For each data point, a latent sample is generated from $q$ using the reparametrisation trick.
- This sample is then fed back into the 'decoder network' which outputs the mean and variance for $p(x \mid z)$.
- Samples of the reconstructed datapoints are generated (although often it's just the mean).
Comparison with Neural Processes¶
VAEs encode a single data point, into a latent representation, and the reconstruct that data point from its latent variable. This is fine if we are learning latent representations for images, but if we want to do this for functions, we need an additional step.
A function graph (e.g. (X, sin(X)), is defined over many sample points. Consider embedding the following function:
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
x = np.arange(-4,5)
y = np.sin(x)
plt.scatter(x,y)

What we think of as our 'function space' is actually defined by the collection of x,y co-ordinates of all these data points. If we proceed niavely, we can just feed this into a VAE, as it wouldn't capture the correct thing. So what we do is introduce an intermediate step, of production a 'function representation', which is a single representation for all the data points. If you have ever done any NLP, it's the same concept as a sentence or document embedding. Hopefully the equivalence is clear between the below diagram and the previous one for a vanilla VAE.
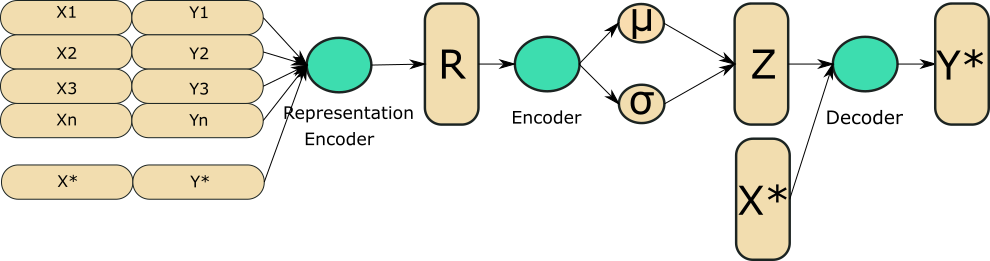
So as the diagrams hopefully illustrate, the two main differences are that we have an additional 'preprocessing' step where we turn multiple points from a function into a single representation, and when we 'reconstruct' we use both the latent representation and the $X^{*}$ we want to predict at.
Pytorch Implementation of Neural Processes¶
Here I have a very simple PyTorch implementation, that follows exactly the same lines as the first example in Kaspar's blog post. I also used his R-Tensorflow code at points the debug some problems in my own code, so a big thank you to him for releasing his code!
import numpy as np
import torch
import matplotlib.pyplot as plt
%matplotlib inline
class REncoder(torch.nn.Module):
"""Encodes inputs of the form (x_i,y_i) into representations, r_i."""
def __init__(self, in_dim, out_dim, init_func = torch.nn.init.normal_):
super(REncoder, self).__init__()
self.l1_size = 8
self.l1 = torch.nn.Linear(in_dim, self.l1_size)
self.l2 = torch.nn.Linear(self.l1_size, out_dim)
self.a = torch.nn.ReLU()
if init_func is not None:
init_func(self.l1.weight)
init_func(self.l2.weight)
def forward(self, inputs):
return self.l2(self.a(self.l1(inputs)))
class ZEncoder(torch.nn.Module):
"""Takes an r representation and produces the mean & standard deviation of the
normally distributed function encoding, z."""
def __init__(self, in_dim, out_dim, init_func=torch.nn.init.normal_):
super(ZEncoder, self).__init__()
self.m1_size = out_dim
self.std1_size = out_dim
self.m1 = torch.nn.Linear(in_dim, self.m1_size)
self.std1 = torch.nn.Linear(in_dim, self.m1_size)
if init_func is not None:
init_func(self.m1.weight)
init_func(self.std1.weight)
def forward(self, inputs):
softplus = torch.nn.Softplus()
return self.m1(inputs), softplus(self.std1(inputs))
class Decoder(torch.nn.Module):
"""
Takes the x star points, along with a 'function encoding', z, and makes predictions.
"""
def __init__(self, in_dim, out_dim, init_func=torch.nn.init.normal_):
super(Decoder, self).__init__()
self.l1_size = 8
self.l2_size = 8
self.l1 = torch.nn.Linear(in_dim, self.l1_size)
self.l2 = torch.nn.Linear(self.l1_size, out_dim)
if init_func is not None:
init_func(self.l1.weight)
init_func(self.l2.weight)
self.a = torch.nn.Sigmoid()
def forward(self, x_pred, z):
"""x_pred: No. of data points, by x_dim
z: No. of samples, by z_dim
"""
zs_reshaped = z.unsqueeze(-1).expand(z.shape[0], z.shape[1], x_pred.shape[0]).transpose(1,2)
xpred_reshaped = x_pred.unsqueeze(0).expand(z.shape[0], x_pred.shape[0], x_pred.shape[1])
xz = torch.cat([xpred_reshaped, zs_reshaped], dim=2)
return self.l2(self.a(self.l1(xz))).squeeze(-1).transpose(0,1), 0.005
def log_likelihood(mu, std, target):
norm = torch.distributions.Normal(mu, std)
return norm.log_prob(target).sum(dim=0).mean()
def KLD_gaussian(mu_q, std_q, mu_p, std_p):
"""Analytical KLD between 2 Gaussians."""
qs2 = std_q**2 + 1e-16
ps2 = std_p**2 + 1e-16
return (qs2/ps2 + ((mu_q-mu_p)**2)/ps2 + torch.log(ps2/qs2) - 1.0).sum()*0.5
r_dim = 2
z_dim = 2
x_dim = 1
y_dim = 1
n_z_samples = 10 #number of samples for Monte Carlo expecation of log likelihood
repr_encoder = REncoder(x_dim+y_dim, r_dim) # (x,y)->r
z_encoder = ZEncoder(r_dim, z_dim) # r-> mu, std
decoder = Decoder(x_dim+z_dim, y_dim) # (x*, z) -> y*
opt = torch.optim.Adam(list(decoder.parameters())+list(z_encoder.parameters())+
list(repr_encoder.parameters()), 1e-3)
Untrained function samples¶
x_grid = torch.from_numpy(np.arange(-4,4, 0.1).reshape(-1,1).astype(np.float32))
untrained_zs = torch.from_numpy(np.random.normal(size=(30, z_dim)).astype(np.float32))
mu, _ = decoder(x_grid, untrained_zs)
for i in range(mu.shape[1]):
plt.plot(x_grid.data.numpy(), mu[:,i].data.numpy(), linewidth=1)
plt.show()

As we can see, we get very 'Gaussian process' like function samples from the prior.
Training¶
def random_split_context_target(x,y, n_context):
"""Helper function to split randomly into context and target"""
ind = np.arange(x.shape[0])
mask = np.random.choice(ind, size=n_context, replace=False)
return x[mask], y[mask], np.delete(x, mask, axis=0), np.delete(y, mask, axis=0)
def sample_z(mu, std, n):
"""Reparameterisation trick."""
eps = torch.autograd.Variable(std.data.new(n,z_dim).normal_())
return mu + std * eps
def data_to_z_params(x, y):
"""Helper to batch together some steps of the process."""
xy = torch.cat([x,y], dim=1)
rs = repr_encoder(xy)
r_agg = rs.mean(dim=0) # Average over samples
return z_encoder(r_agg) # Get mean and variance for q(z|...)
def visualise(x, y, x_star):
z_mu, z_std = data_to_z_params(x,y)
zsamples = sample_z(z_mu, z_std, 100)
mu, _ = decoder(x_star, zsamples)
for i in range(mu.shape[1]):
plt.plot(x_star.data.numpy(), mu[:,i].data.numpy(), linewidth=1)
plt.scatter(x.data.numpy(), y.data.numpy())
plt.show()
all_x_np = np.arange(-2,3,1.0).reshape(-1,1).astype(np.float32)
all_y_np = np.sin(all_x_np)
def train(n_epochs, n_display=3000):
losses = []
for t in range(n_epochs):
opt.zero_grad()
#Generate data and process
x_context, y_context, x_target, y_target = random_split_context_target(
all_x_np, all_y_np, np.random.randint(1,4))
x_c = torch.from_numpy(x_context)
x_t = torch.from_numpy(x_target)
y_c = torch.from_numpy(y_context)
y_t = torch.from_numpy(y_target)
x_ct = torch.cat([x_c, x_t], dim=0)
y_ct = torch.cat([y_c, y_t], dim=0)
# Get latent variables for target and context, and for context only.
z_mean_all, z_std_all = data_to_z_params(x_ct, y_ct)
z_mean_context, z_std_context = data_to_z_params(x_c, y_c)
#Sample a batch of zs using reparam trick.
zs = sample_z(z_mean_all, z_std_all, n_z_samples)
mu, std = decoder(x_t, zs) # Get the predictive distribution of y*
#Compute loss and backprop
loss = -log_likelihood(mu, std, y_t) + KLD_gaussian(z_mean_all, z_std_all,
z_mean_context, z_std_context)
losses.append(loss)
loss.backward()
opt.step()
if t % n_display ==0:
print(f"Function samples after {t} steps:")
x_g = torch.from_numpy(np.arange(-4,4, 0.1).reshape(-1,1).astype(np.float32))
visualise(x_ct, y_ct, x_g)
return losses
train(9001);




As we train the network, we seem to get good agreement inside the data points and less certainty as we extrapolate - looks great!
Trouble in paradise¶
In my implementation, there is a fairly innocuous but crucial detail that I haven't really talked about. That's the weight initialization I have used. One would imagine this to be a fairly inconsequential thing, but it really, really doesn't seem to be. For example, lets repeat the above steps, but with the default PyTorch initialization.
repr_encoder = REncoder(x_dim+y_dim, r_dim, None) # (x,y)->r
z_encoder = ZEncoder(r_dim, z_dim, None) # r-> mu, std
decoder = Decoder(x_dim+z_dim, y_dim, None) # (x*, z) -> y*
opt = torch.optim.Adam(list(decoder.parameters())+
list(z_encoder.parameters())+list(repr_encoder.parameters()), 1e-3)
train(9001, 4500);



Huh, it seems to basically collapse to a deterministic function. Let's try Xavier normal.
repr_encoder = REncoder(x_dim+y_dim, r_dim, torch.nn.init.xavier_normal_) # (x,y)->r
z_encoder = ZEncoder(r_dim, z_dim, torch.nn.init.xavier_normal_) # r-> mu, std
decoder = Decoder(x_dim+z_dim, y_dim, torch.nn.init.xavier_normal_) # (x*, z) -> y*
opt = torch.optim.Adam(list(decoder.parameters())+
list(z_encoder.parameters())+list(repr_encoder.parameters()), 1e-3)
train(9001, n_display=9000);


Ok, this is strange. Let's just repeat the first experiment, but this time, train it for a bit longer.
repr_encoder = REncoder(x_dim+y_dim, r_dim) # (x,y)->r
z_encoder = ZEncoder(r_dim, z_dim) # r-> mu, std
decoder = Decoder(x_dim+z_dim, y_dim) # (x*, z) -> y*
opt = torch.optim.Adam(list(decoder.parameters())+
list(z_encoder.parameters())+list(repr_encoder.parameters()), 1e-3)
train(25001, n_display=12500);



So even for the previous success, it turns out with a bit more training we completely destroy the positive aspects we saw. Even at just a small bit of extra training (12500 vs 9000), things look a lot less GP like.
What does this mean?¶
Well, firstly, this is not unique to Neural GPs. Just because we have used a distribution rather than a point estimate, doesn't mean these methods give us proper bayesian inferences or does what we want. Even though above we have an approximate posterior, that posterior is essentially just a point mass.
One of the most important parts of a Bayesian approach is getting reliable uncertainty estimates - as the above shows, even on a toy example, it's possible to get a Neural process which has no uncertainty predicting at x=-4, where it has never seen a single piece of data at that point.
In addition, much of the nice results we can see appear to be the result of both very particular initialization and a 'just right' amount of training.
What could be causing this in this instance?¶
In the normal VAE formulation, the prior is a standard gaussian. This means completely collapsing the posterior has some cost associated to it. If we consider the analytical KLD for two gaussians:
$log \frac{\sigma_{2}}{\sigma_{1}} + \frac{\sigma_{1}^{2} + (\mu_{1}-\mu_{2})^{2}}{2 \sigma_{2}^{2}}-\frac{1}{2}$
In this notation, our approximate posterior is denoted by subscript 1, and the prior subscript 2. This means $\sigma_{2}=1$ in the univariate case.
$log \frac{1}{\sigma_{1}} + \frac{\sigma_{1}^{2} + (\mu_{1}-\mu_{2})^{2}}{2}-\frac{1}{2}$
As we see, making sigma approach zero has some small cost, but the fact it is inside the log means this effect is rather stunted. $\sigma_{1}$ has to get very, very small indeed before we get a substantial cost. In fact, the difference in the means is clearly the dominating factor here. So even for a vanilla VAE, there actually isn't much stopping the posterior variance ending up quite small indeed.
In Neural GPs the KLD divergence is computed with an 'adaptive prior' which is given by $KL(q(z \ | \ context, \ target) \ || \ q(z \ | \ context))$. Both of these are from the same network.
x_context, y_context, x_target, y_target = random_split_context_target(
all_x_np, all_y_np, np.random.randint(1,4))
x_c = torch.from_numpy(x_context)
x_t = torch.from_numpy(x_target)
y_c = torch.from_numpy(y_context)
y_t = torch.from_numpy(y_target)
x_ct = torch.cat([x_c, x_t], dim=0)
y_ct = torch.cat([y_c, y_t], dim=0)
mu_ct, std_ct = data_to_z_params(x_ct,y_ct)
mu_c, std_c = data_to_z_params(x_c,y_c)
print("mu context, target: " ,mu_ct.data.numpy(), "\n mu context: ",mu_c.data.numpy())
print("*"*40)
print("sigma context, target: " ,std_ct.data.numpy(), "\n sigma context: ",std_c.data.numpy())
z_mean_all, z_std_all = data_to_z_params(x_ct, y_ct)
z_mean_context, z_std_context = data_to_z_params(x_c, y_c)
print("KLD value: ",KLD_gaussian(z_mean_all, z_std_all, z_mean_context, z_std_context).data.numpy())
Because the network adapts both the prior and the posterior, it can 'cheat' and give us a very small standard deviation for both, and at little penalty. To do this it has to learn to place the means also quite close together, which means we get a very small difference from including target points or not.
Summary¶
In this post, I have briefly introduced Neural Processes, provided a PyTorch implementation, and provided some examples of undesirable behaviour. Essentially, iniatlization seems to be incredibly important, and failure to get this right seems to destroy the 'nice' sampling behaviour we can see. This appears at least in part to be due to the 'adaptive prior' formulation of the Neural Process which provides no barrier to the network collapsing the posterior to a near point estimate, thus removing much of the nice behaviour.
In my next post, I plan to delve a bit deeper into the topic of uncertainty in deep methods, and talk about a few nice recent suggestions for potentially improving matters.